Backup your servers automatically to Amazon AWS S3
By Vince
This post will explain how I backup mine and my clients Linux servers to Amazon’s S3 file storage service via bash shell scripts.
It’s cheap, quick, and it takes care of off-site backups. I prefer to use a different provider than my hosting company in case of major system disruption. I hope everyone has great documentation on how to stand up a new server! With this design, it gives you ultimate control over how many backups you want, and how long to keep them. Amazon will actually take care of deleting old backups based on your preferences.
The first step is to make sure you have an S3 account setup (billing, etc) and configure the user that will have access to write to S3. S3 is organized into buckets, which is the place you store files.
This is by FAR the most complex part of this, securing AWS S3 access through IAM (Identity Access Manager). Basically you are creating a user, and giving it permissions to our S3 “bucket”. There are two places to configure permissions/policies, on the bucket itself, and in the global account settings or IAM. We are only going to configure an IAM user which has access to our bucket.
- Let’s create our file storage bucket, go to the S3 console: https://console.aws.amazon.com/s3/
- If you don’t have an Amazon AWS user/account, create one now.
- Once you’re logged into the S3 management console, click “Create Bucket”.
- Give it a bucket name, and pick a region “close” to where your servers are. Make the bucket name something you will recognize and a long name, it has to be unique in the amazon system.
- Write down the Region and Bucket Name for later steps.
- Click Next and set the properties, we can control versions (if people are editing the files, which we are not), and logging.
- We only want to enable logging, so click the logging box, and click “Enable Logging”. This will give us a record of requests made to this bucket for auditing.
- Inside the logging options, select the target bucket we just created, and for the prefix, set it to something like “logs”. This will save them in a separate folder from our backups.
- Click Next which goes to Set Permissions, there should only be one user that has access to this bucket (via the web console) which is the user your logged in with.
- In the section below “Manage Public Permissions”, make sure NOTHING is checked. We don’t want the public to have any access to this. The reason AWS has this option is you can create a web site that is served through S3.
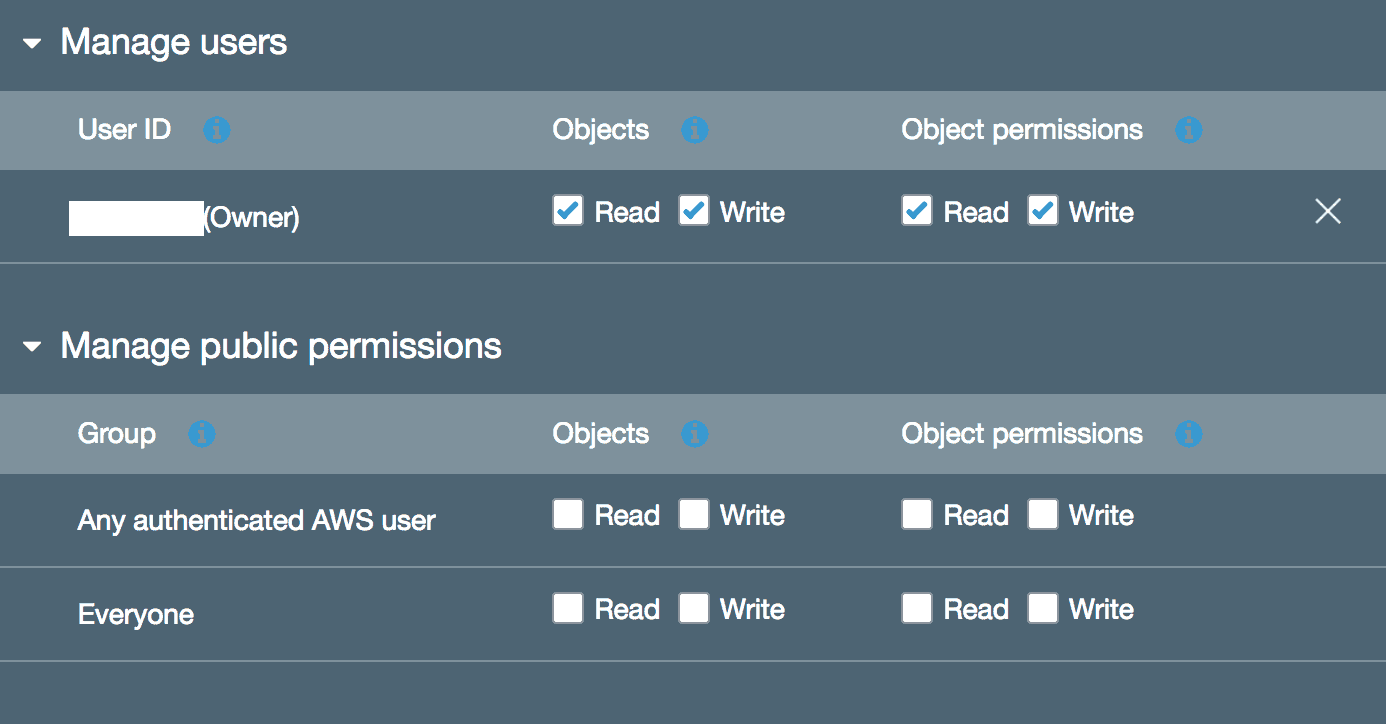
- Click Next and Review your settings, then finish with “Create Bucket”.
Bucket created!
- Now our bucket is created, let’s setup some file deletion parameters so we don’t keep backups forever (unless you want to). If they stick around too long, you will notice your amazon bill starts to creep higher each month.
- Once you select the bucket to manage, click on the “Management” tab.
- Make sure “Lifecycle” is selected.
- Click “Add lifecycle rule”
- Enter a name, let’s use - “90 day cleanup”
- We don’t need a scope, it will apply to the whole bucket so keep that blank
- Click Next, now we are on the “Transition” screen.
- Here we are going to move our backups into a cheaper area of AWS S3, called “infrequent access” or IA. This has the same access rules as normal, but costs less since we don’t need to get our backups quickly. This is only allowed after 30 days of having the file in normal access.
- Check “Current Version”
- Click “Add Transition”
- Select “Transition to Standard IA After”. Don’t select glacier, that takes too long to recover backups.
- Put 30 in the box, so after 30 days we are going to switch the files.
- Click Next
- On the “Expiration” screen, check “Current Version”
- Check “Expire current version of object”
- Put 90 into the days field, so after 90 days it will be expired
- Check “Clean up incomplete multipart uploads”
- Put 7 into the days field. This will make sure bad uploads get removed.
- Click Next, review and click Save.
Files will now get removed after 90 days. If you want to keep them longer, feel free to change the expiration value. You can also create two buckets, a long term backup and a short term backup if you wish, then don’t set the expiration on the long term bucket (make sure to setup a transition though). This way you can have a long term audit (or yearly backup).
- Now we have our bucket created, we need to setup access to it via the IAM console. This is where it gets confusing, since we are setting up policies in Amazons own policy language.
- So let’s create our IAM user and give them access to our bucket, go to the IAM console (you can click IAM in the menu bar if logged in, or goto): https://console.aws.amazon.com/iam/
- First we need to create a policy, so click “Policies” and “Create Policy”.
- Click “Select” for Create Your Own Policy
- Policy Name - Name this something unique for this backup
- Description
- Policy Document - the actual policy, the language is Amazon’s creation. Below is an example that you can work with. It’s in standard JSON format. I am not going to comment inside the policy so you can just copy/paste if you like.
- You need to replace BUCKETNAME in two places with the name of the bucket we created above.
- I have also added in a “condition” which you can remove if you like, this restricts access to this user and the bucket to a couple IP addresses. If you are backing up servers that have unique internet IP addresses, then this will make it very restrictive. If the devices backing up are coming from a different IP address every time, then you can remove the entire condition section (so delete “Condition”:{ on down to the the curly brace that matches it). I have two examples, one with the condition, and one without. Copy which one you like.
- Only copy the section you want, and only copy the curly braces and everything in between.
- Policy Document - the actual policy, the language is Amazon’s creation. Below is an example that you can work with. It’s in standard JSON format. I am not going to comment inside the policy so you can just copy/paste if you like.
# Example with an IP address restriction
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"s3:PutObject",
"s3:PutObjectAcl",
"s3:GetObject",
"s3:GetObjectAcl"
],
"Effect": "Allow",
"Resource": [
"arn:aws:s3:::BUCKETNAME",
"arn:aws:s3:::BUCKETNAME/*"
],
"Condition": {
"IpAddress": {
"aws:SourceIp": [
"x.x.x.x/32",
"y.y.y.y/32"
]
}
}
}
]
}
#
# Example without the "Condition" so any ip address can use this user and bucket it connects to
#
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"s3:PutObject",
"s3:PutObjectAcl",
"s3:GetObject",
"s3:GetObjectAcl"
],
"Effect": "Allow",
"Resource": [
"arn:aws:s3:::BUCKETNAME",
"arn:aws:s3:::BUCKETNAME/*"
]
}
]
}
- So what are the components inside the policy document?
- Version - this is the code language we are using, always use the latest
- Statement - this is an array of things we are allowing or denying
- Action - what the statement is allowed to do (note we are not allowing list here for security)
- “s3:PutObject” - Inside the S3 environment, we are allowed to add objects, AKA Put
- “s3:PutObjectAcl” - On those objects we can change their file permissions (needed for Unix)
- “s3:GetObject” - We are allowed to get these objects once we put them
- On a side note, if you want to really restrict this, remove the Get objects so the backup users can only put. That way your backups are “hidden” and someone has to log into the console to download them.
- “s3:GetObjectAcl” - Get the current file permissions on objects
- For a full list of the actions: http://docs.aws.amazon.com/IAM/latest/UserGuide/list_s3.html
- Final step - Click “Validate Policy” once you have it finished
- Click “Create Policy” if it gives you the green light (no errors)
Policy created!
- Now we have to create a user and associate the policy to it, which will give us the keys to use for the AWS client.
- Stay inside the IAM tool: https://console.aws.amazon.com/iam/ and click on users.
- Click “Add user”
- Fill out the username field
- Check the box that says “Programmatic access” - since this will be an API only user, not logging into the console
- Click “Next: permissions”
- Click “Attach existing policies directly”
- Now you need to find the policy created above, if the name is hard to find, you can change the filter
- To change the filter, click on the dropdown that says “Policy Type” and click “Customer Managed”
- The policy you created should show up there
- Check the box to the left of policy you want to attach to this user
- Click “Next: review”
- Double check and click “Create user”
- IAM will now display the “Access Key” and “Secret access key” (click show first).
- Copy these values down, we will need them for the client installation step which is up next!
User Created! Policy Attached! Almost there.
If you have made it this far, then the S3 bucket is created, we have a user and secured access to it.
Now we need to install the Amazon AWS client package. This varies on OS, so you can check out the docs here: http://docs.aws.amazon.com/cli/latest/userguide/installing.html
We are going to install the Ubuntu Linux AWS client (should be the same aws bundle for all Linux distros):
# you need to make sure unzip is installed first
apt-get install unzip
# download the client from amazon
curl "https://s3.amazonaws.com/aws-cli/awscli-bundle.zip" -o "awscli-bundle.zip"
unzip awscli-bundle.zip
# here we are just installing the client into the local system
# do this as ROOT
./awscli-bundle/install -i /usr/local/aws -b /usr/local/bin/aws
# the last step is to configure the client, you will need a few things
# such as your Client ID, Secret ID, region
# Here we enter the information from above.
# The regions you can enter are listed here:
# http://docs.aws.amazon.com/general/latest/gr/rande.html
# Use the short version, so "us-west-1" or "us-east-1"
# The region is listed in the top/right corner of the AWS S3 screen.
aws configure
-----
AWS Access Key ID: 123123123123
AWS Secret Access Key: 123123123123
Default region name: us-west-1
Default output format: json
#
# This information is stored in your home directory, 'ls -al ~/.aws'
AWS should be configured, and you can check that access to your bucket is working by running:
# Create a test file to upload
touch testcopy
aws s3 cp ./testcopy s3://BUCKETNAME/test/
upload: ./testcopy to s3://BUCKETNAME/test/testcopy
# Success!
Note, since we are not allow list access, you cannot run:
aws s3 ls
You will get access denied. This is in case someone gets our server, they can’t download other backups easily since you must know the filename explicitly.
Now we can setup the bash script that ties this all together
# Open a new file with your favorite editor
vi backup_all_s3.sh
# Paste these contents-------
#!/bin/bash
PATH=$PATH:/usr/local/bin
nowis=`date +%H-%M-%S-%F`
host=`uname -n`
crontab -l > /root/crontab
cd /tmp
echo "backup logs for $host" > /tmp/backupall
echo "backup errors for $host" > /tmp/backupallerrors
tar cfz $host-backup-$nowis.tar.gz /etc /root >>/tmp/backupall 2>>/tmp/backupallerrors
aws s3 cp /tmp/$host-backup-$nowis.tar.gz s3://BUCKETNAME/DIRECTORY/ --sse AES256 >>/tmp/backupall 2>>/tmp/backupallerrors
if [ $? -eq 0 ]
then
rm /tmp/$host-backup-$nowis.tar.gz
else
cat /tmp/backupall /tmp/backupallerrors | sendmail root
fi
There are a few things going on in the script that you should be aware of.
# This is to backup the crontab file in case we need to re-create the server, optional
crontab -l > /root/crontab
# We are assuming you want to use the /tmp directory for building this backup, so change that to something else if you wish
# Here we are only backing up the /etc and /root directories. If you need more, just add or change them.
tar cfz $host-backup-$nowis.tar.gz /etc /root >>/tmp/backupall 2>>/tmp/backupallerrors
# Here you must replace BUCKETNAME with your S3 Bucket, and DIRECTORY with whatever you like.
# You don't have to put them into a directory on S3, but it makes it cleaner when you login
aws s3 cp /tmp/$host-backup-$nowis.tar.gz s3://BUCKETNAME/DIRECTORY/ --sse AES256 >>/tmp/backupall 2>>/tmp/backupallerrors
The script checks the return value from the aws copy to make sure it copied correctly. If the return wasn’t 0 (0 is success), then we email the logs to root. You need to have postfix or some other mail sender already setup for this to work.
Also NOTE: those are backticks after the equal signs, so if ` isn’t formatting properly when you copy/paste, make sure to change them. Its the top/left key on the keyboard. This tells Linux to run the command and set the output of it to the variable, which you are naming on the left of the = sign. So variable=executethiscommand
Now let’s make the file we just created executable:
chmod +x backup_all_s3.sh
And let’s make sure this works:
./backup_all_s3.sh
# If it works successfully, you shouldn't see any output.
Login to your AWS S3 console: https://console.aws.amazon.com/s3/
Look for your first backup file! It should be named “hostname-backup” with the current date on the end.
Now we can add this to our crontab (if using Linux) and it will backup whenever we like.
crontab -e
# Once inside the cron editor, paste a line like this,
# but replace the /opt/ path with where you saved the script
5 3 * * * /opt/backupall.sh
Backup’s configured!
Was that a lot to do, yup, but now your backups are set.
The most important thing to remember is, if you haven’t tested your backups recently then backups don’t exist.
To test backups, make sure the files are good in the tar.gz we are creating (download it from AWS s3) and run through your restore procedure on a new host. Don’t have a procedure? Make one, it’s impossible to remember all the steps to install a new server properly and securely these days, so run through it.